GENA-LM: российская языковая модель, которая помогает увидеть невидимые закономерности в ДНК
13 апреля 2026
GENA-LM: российская языковая модель, которая помогает увидеть невидимые закономерности в ДНК
- 233
- 0
- 3
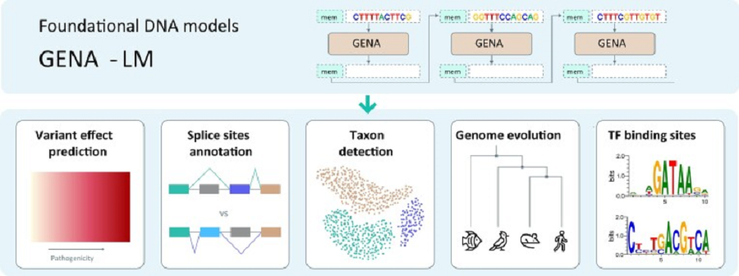
Фундаментальные модели GENA-LM.
Рисунок в полном размере.
-
Автор
-
Редакторы
Статья на конкурс «Био/Мол/Текст»: Нейросети уже давно вышли за рамки обычного языка: сегодня они уверенно справляются с биологическими последовательностями. GENA Language Models — семейство языковых моделей, созданное исследователями Института искусственного интеллекта AIRI для анализа геномных данных и обнаружения в них скрытых закономерностей. Модель учитывает до 36 тысяч нуклеотидов, при этом умея выявлять сложные взаимосвязи, что позволяет предсказывать влияние генетических вариантов, обнаруживать регуляторные элементы и перспективе способствовать развитию медицины. Далее, я расскажу, как нейросети, использующие принципы обработки последовательностей, схожих с теми, что используются в моделях человеческого языка, могут как бы «читать» и интерпретировать ДНК, и почему такой подход меняет способы работы биологов с геномными данными.

Конкурс «Био/Мол/Текст»-2025/2026
Эта работа опубликована в номинации «Школьная» конкурса «Био/Мол/Текст»-2025/2026.
Генеральный партнер конкурса — международная инновационная биотехнологическая компания BIOCAD.
Партнер номинации — Благотворительный фонд «Белая лилия», который поддерживает школьников, студентов профильных вузов, научных коллективов врачей и ученых по разработке и созданию прорывных технологий в области медицины.
«Книжный» спонсор конкурса — «Альпина нон-фикшн»
Когда ДНК начинает вести себя как язык
Благодаря быстрому развитию секвенирования, сегодня биология в полный рост сталкивается с фундаментальной проблемой: мы умеем быстро получать последовательности ДНК, но отнюдь не всегда умеем понимать их функциональный смысл [4], [5]. Геном человека — это около 3 миллиардов пар нуклеотидов. Если представить его в форме текста, получилась бы многотомная книга, содержание которой далеко не всегда поддаётся разбору привычными методами.
Сложность связана с тем, что функциональные элементы — промоторы, энхансеры, сайты связывания транскрипционных факторов, участки разделения — не имеют строгой, однозначной структуры. Их сигналы могут быть растянуты на тысячи нуклеотидов. Они способны перекрываться между собой или проявляться только в сочетании с отдаленными элементами. Классические методы анализа ДНК, основанные на поиске коротких мотивов и локальных признаков, плохо улавливают такие дальнодействующие зависимости.
Поток геномных данных в последние годы вырос настолько, что старые способы их анализа перестали справляться. Постепенно в 2020-х годах стало понятно: сходство между генетическими последовательностями и человеческими языками — это не просто удобная аналогия. У них действительно много общего в своей структуре. И ДНК, и любой текст на человеческом языке представляют собой цепочки символов из ограниченного алфавита — будь то четыре нуклеотида, 20 аминокислот или буквы из алфавита какого-либо человеческого языка. В этих цепочках эволюция, биологическая или культурная, оставляет следы в виде устойчивых статических закономерностей. Смысл каждого элемента оказывается завязан на окружение, и задача моделей — уловить, насколько вероятно появление того или иного символа в данном контексте.
Эти наблюдения подчеркнули глубокое структурное родство ДНК и языка: и те, и другие состоят из символов, объединенных в устойчивые мотивы («слова») и более крупные функциональные блоки. Эта аналогия стала концептуальной основой для применения трансформеров — архитектуры нейросетей, изначально разработанной для обработки длинных текстов и поиска в них важных контекстных связей (лежит в основе GPT и BERT), — для анализа ДНК. Именно трансформеры оказались тем инструментом, который лучше всего решает такую задачу угадывания пропущенных или следующих элементов, что и открыло им дорогу в геномные исследования.
Я всегда говорю, что [наша модель GENA-LM] похожа на ChatGPT, но для геномов. LM в названии расшифровывается как Language Model, то есть «Языковая модель». Наверное, единственное принципиальное отличие заключается в том, что генеративные модели, к которым относится GPT и ее аналоги, не только считывают информацию, но и выдают ее обратно на том же самом языке, на котором мы им эту входную информацию даем. Модели наподобие GENA относятся к так называемым энкодерам. Они умеют читать, но информацию, которую они выдают обратно, мы получаем только в понятном для компьютера формате, на вход подаем ДНК, а она нам на выходе — код.
Как устроена GENA-LM: ключевые технические особенности
GENA-LM — семейство языковых моделей, основанное на трансформерной архитектуре, адаптированной под специфику генетических последовательностей [6]. Несмотря на знакомый общий принцип, решение содержит ряд важных инженерных и научных нововведений, таких как:
- Работа с длинным контекстом. Ранее в качестве базового подхода использовались модели по типу DNABERT [7] — один из первых успешных трансформеров для анализа ДНК, способный анализировать примерно 500 пар нуклеотидов (и до нескольких тысяч в DNABERT-2). Именно по сравнению с этим безлайном особенно заметны преимущества GENA-LM, которая поддерживает контекст до целых 36 000 нуклеотидов [6], а при использовании рекуррентной памяти (RMT) — еще больше, и позволяет учитывать дальнодействующие регуляторные взаимодействия.
Для геномики это очень важно: элементы регуляции могут взаимодействовать на расстояниях, которые выходят далеко за пределы типичных окон анализа. - Масштабное предобучение. Модель проходит предобучение без учителя, как бы «угадывая» замаскированные нуклеотиды по окружению и постепенно формируя внутреннее представление структуры генома. Это аналог языковых моделей, которые учатся на огромных корпусах текстов, накопленных человечеством. После этого GENA-LM можно дообучать под конкретные задачи — от детекции промоторов до предсказания сайтов связывания транскрипционных факторов (рис. 1).
- Мультивидовой подход. Ученые-исследователи создали версии модели для человека, дрожжей, арабидопсиса, дрозофилы, а также мультивидовую модель. Такой подход помогает изучать эволюционную сохранность сигнальных элементов и переносить знания о регуляторных мотивах между организмами.
 с помощью GENA-LM")
Рисунок 1. Выявление ДНК-мотивов транскрипционных факторов (ТФ) с помощью GENA-LM. (а) — логотипы мотивов для трех ТФ; (б) — профиль средних значений важности токенов вдоль последовательности; вертикальные линии показывают 200-п.н. регион предсказания; (в) — частота токенов из топ-5% по важности; X-ось — доля этих токенов относительно всех появлений; линия 0,05 — порог отображения; (г) — боксплоты распределения важности токенов по FIMO q-value (медиана, межквартильный диапазон, 5-й и 95-й перцентили).
Возможности GENA-LM: прикладные применения
После удачной настройки GENA-LM показывает одни из лучших результатов в ряде задач функциональной геномики.
- Предсказание регуляторных элементов. Модель умеет находить разные регуляторные участки ДНК — будь то промоторы, энхансеры или другие сайты связывания. Это особенно важно для организмов, где экспериментальных данных мало или нет вовсе. При этом точность предсказаний выше, если использовать модель, обученную на близком виде; мультивидовые модели позволяют работать с более удаленными видами, но с меньшей детализацией.
- Интерпретация генетических вариантов. Однонуклеотидные варианты, особенно редкие, часто оказываются «клинически неинтерпретируемыми». GENA-LM позволяет оценить, может ли мутация нарушать сигналы для сплайсинга, промоторную активность или работу регуляторных мотивов. Это важный шаг для исследований in silico, позволяющий оценивать потенциальное влияние генетических вариантов и формировать гипотезы для дальнейших экспериментов.
- Идентификация мотивов. Модель находит как известные, так и новые короткие последовательности, лежащие в основе регуляторных механизмов. Такие мотивы строят своего рода «грамматику» генома, и их точное определение помогает понять, как именно формируется экспрессия генов.
Почему это важно: взгляд в будущее биологии и медицины
Появление GENA-LM и аналогичных моделей знаменует переход геномики от описательной стадии к предсказательной. Теперь исследователь может не просто фиксировать факты, а даже получать вероятностные оценки того, как участки ДНК будут себя вести еще до того, как начнется эксперимент.
В контексте клинической генетики GENA-LM помогает исследователям формировать гипотезы о влиянии редких или малоизвестных вариантов ДНК, дополняя информацию из баз данных, таких как ClinVar.
Кроме того, такие модели по-настоящему ускоряют фундаментальные исследования. Ученые могут быстрее формулировать гипотезы о плохо изученных участках генома, выбирать кандидатов для экспериментов и сокращать объем лабораторной работы.

Рисунок 2. Архитектура и задачи GENA-LM. (а) — архитектура GENA-LM на базе трансформеров предварительно обучена на ДНК-последовательностях с использованием «маскирования» отдельных элементов последовательности (MLM); (б) — задачи оценки GENA включают предсказания активности промотеров и энхансеров, сайтов сплайсинга, профилей хроматина и силы полиаденилирования; (в) — модели, дообученные под конкретные задачи, доступны через веб-сервис GENA-Web; (г) — медианная длина токена, используемая в модели, — 9 п.н., как показано в этом распределении длин; (д) — представление повторяющихся элементов для 100 самых длинных токенов; (е) — точности моделей GENA на задаче MLM показывают, что модели с большим числом параметров достигают лучших результатов.
Доступность и практическое использование
Все модели GENA-LM доступны в открытом доступе на GitHub и HuggingFace. Для пользователей, не желающих настраивать программное окружение, предусмотрен веб-интерфейс, позволяющий загружать последовательности и получать аннотации напрямую. Это делает современные методики анализа доступнее для широкого круга биологов и биоинформатиков.
Заключение
GENA-LM — один из первых проектов, который применяет передовые методы обработки языка к ДНК в масштабах, действительно значимых для биологии. Он демонстрирует, что архитектуры, созданные для человеческого языка, способны выявлять глубокие закономерности в геномах и служить надежным инструментом как для фундаментальных исследований, так и для клинической практики.
Если развитие подобных моделей продолжится, они могут стать для биологов таким же повседневным инструментом, как ПЦР или секвенирование. И, возможно, помогут открыть новые уровни организации генома, которые до сих пор оставались скрытыми.
Литература
- Žiga Avsec, Natasha Latysheva, Jun Cheng, Guido Novati, Kyle R. Taylor, et. al.. (2026). Advancing regulatory variant effect prediction with AlphaGenome. Nature. 649, 1206-1218;
- История развития искусственного интеллекта и его пришествия в биологию;
- Как языковые модели покорили мир белков;
- Геном человека: как это было и как это будет;
- 12 методов в картинках: секвенирование нуклеиновых кислот;
- Veniamin Fishman, Yuri Kuratov, Aleksei Shmelev, Maxim Petrov, Dmitry Penzar, et. al.. (2025). GENA-LM: a family of open-source foundational DNA language models for long sequences. Nucleic Acids Research. 53;
- Yanrong Ji, Zhihan Zhou, Han Liu, Ramana V Davuluri. (2021). DNABERT: pre-trained Bidirectional Encoder Representations from Transformers model for DNA-language in genome. Bioinformatics. 37, 2112-2120.



Комментарии
0Чтобы оставить комментарий, необходимо
войти