Я б в биоинформатики пошёл, пусть меня научат!
30 апреля 2014
Я б в биоинформатики пошёл, пусть меня научат!
- 20331
- 0
- 27

Нет, на самом деле все выглядит не так. Биоинформатик сидит перед простой персоналкой за заваленным статьями столом (а то и просто держит на коленях ноутбук), и лишь изредка логинится на суперкомпьютер.
-
Автор
-
Редакторы
Биология не раз переживала новое рождение: быв сначала «полевой» наукой, изучавшей животных и растения, в XX веке она значительно переместилась в лаборатории, концентрируясь на молекулярных основах жизни и наследственности. В XXI веке история двинулась дальше: многие эксперименты теперь проводятся на компьютере, а материалом для изучения являются последовательности белков и ДНК, а также информация о строении биологических молекул. В этой статье мы дадим несколько советов тем, кто решил связать свою карьеру с компьютерной биологией, став, тем самым, биоинформатиком.
Обратите внимание!
Спонсор публикации этой статьи — Лев Макаров.
В наше время в мире никого не удивишь уже названием профессии «компьютерный биолог» или «биоинформатик», хотя еще несколько десятков лет назад эти сферы деятельности — биология и компьютеры — казались совсем непересекающимися, а еще за несколько десятков лет до того никаких компьютеров не было вовсе. Причем сейчас этот термин включает в себя уже достаточно много отдельных занятий, требующих разной подготовки и разного взгляда на науку и ее место в жизни: биоинформатик, специалист по обработке информации, разработчик баз данных, программист, куратор онтологий, специалист по молекулярному моделированию — все они занимаются разными вещами, хотя со стороны их отличить будет непросто. Все это без намеков говорит нам, что компьютеры прочно вошли в будни биологов, причем это не только е-мейл и фейсбучек, но и масса более специальных навыков, без которых исследователю сейчас и в будущем уже не обойтись (см. врезку). Студент вы или профессор, — никогда не поздно начать совершенствовать свои навыки биоинформатика !
Для ясности биоинформатиками будем называть всех биологов, в работе которых компьютеры играют роль бóльшую, чем просто печатная машинка, хотя в российской традиции собственно под биоинформатиками имеют в виду тех, кто занимается изучением закономерностей биологических текстов — последовательностей белков и ДНК, — а моделирование динамики и свойств биомолекул, например, чаще называют молекулярным моделированием.
Выбор оружия за вами
Сейчас создано такое количество разнообразных биоинформатических программ, что сделать оригинальное компьютерное исследование можно, и не программируя самостоятельно; надо только выбрать подходящее ПО. Однако не стоит слишком расслабляться: чтобы получилось что-то хорошее, надо сначала как следует понять, что же эти программы делают, и какая математическая теория лежит в их основе. Вы же не пойдете в лабораторию ставить полимеразную цепную реакцию, предварительно не узнав, что это такое и для чего нужно ? Ну так вот и с компьютерами то же самое. Биоинформатические программы, по сути, являются аналогами оборудования и методик в «мокрой» молекулярно-биологической лаборатории. (Кстати, на контрасте со словом «мокрый» биоинформатические лаборатории все чаще сейчас называют «сухими» [8].) Поэтому, хотя от вас и не требуется вчитываться в каждую строчку исходного кода, представлять себе общие принципы работы программ совершенно необходимо.
Ну, мы надеемся, что не пойдете. — Ред.
Разные программы часто воплощают один и тот же теоретический подход, но все-таки адаптированы для решения разных практических задач. Например, при «сборке» генома из отдельных последовательностей ДНК [9], получаемых в результате работы автоматических секвенаторов, в случае «длинных» (сотни остатков нуклеотидов) прочтений используется алгоритм, основанный на перекрывании (Overlap-Layout-Consensus), в то время как для работы с наборами «коротких» (десятки остатков нуклеотидов) фрагментов лучше подходят графы де Брёйна. И выбор правильной программы не только сэкономит вам массу времени, но и вообще принципиально обеспечит (или не обеспечит) выполнимость поставленной задачи.
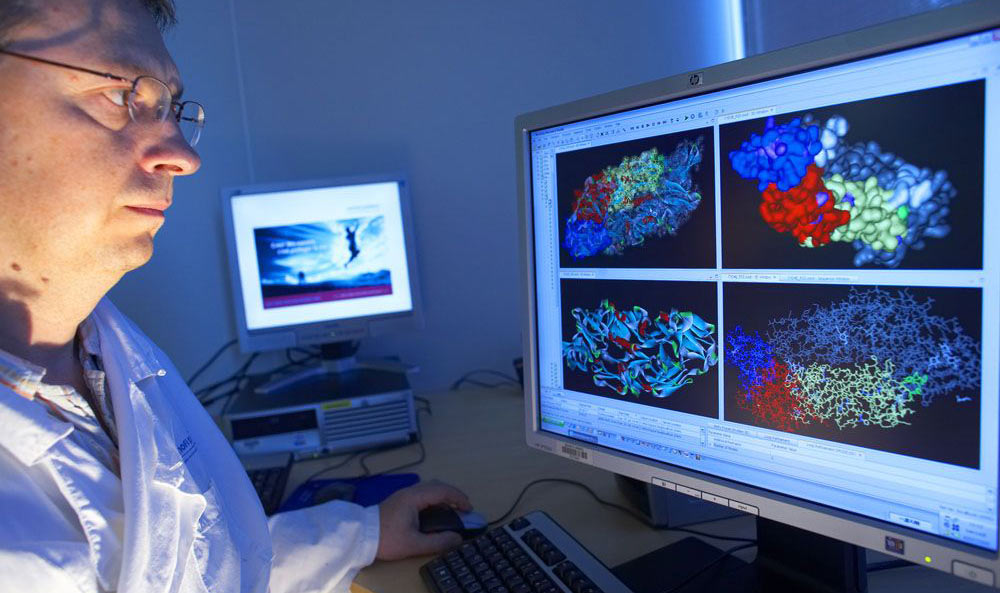
Хотя иной раз на мониторе биоинформатика и появляются занятные картинки (в данном случае — гликопротеин лихорадки Денге), чаще всего там можно увидеть текстовое окошко с непонятными колонками цифр или строчками букв.
Держите все под контролем
Одна из главных опасностей, что компьютер запросто может выдать неправильный результат, специально никак не просигнализировав об этом. Отсутствие сообщения об ошибке еще не говорит о том, что полученный результат правильный. Подав программе дикие данные на вход или просто использовав неправильные настройки, неизбежно получишь дикий ответ, и чрезвычайно важно постоянно помнить о такой возможности и уметь проверять, что полученное имеет хоть какое-то отношение к действительности. Проще всего убедиться, что все работает как следует, запустив программу для данных, ответ для которых уже известен, и убедиться, что именно он и получается. Часто для маленьких наборов данных вычисления можно провести буквально вручную, и тогда сверить ответ с получаемым на компьютере особенно занятно: если он отличается, то либо не права машина, либо вы. Но положительного результата в этом случае уже не получить — это точно.
Биохимические эксперименты никогда не проводят без отрицательных и/или положительных «контролей», так вот привыкайте и на компьютере делать то же самое. Контролем в биоинформатике последовательностей служит, как правило, проверка модели на неких случайных данных. С выбором модели генерации случайных данных надо быть очень и очень аккуратным. Дважды проверяйте, что все было без ошибок, и, главное, что полученные результаты имеют какой-то смысл, — иначе вас неизбежно подкараулят «открытия» на ровном месте.

Если программировать достаточно много, все предстает в другом свете.
сайт molecularecologist
Вы ученый, а не программист
Как известно, лучшее — враг хорошего. Помните, что в вашей работе важны свежие мысли и новизна результатов, а не красота исходников программы. Превосходно оформленный и документированный код, который не дает правильного ответа, несомненно, никуда не годится по сравнению с примитивным скриптом, который дает его. Другими словами, красоту в программу следует привносить только после того, как вы не раз уже убедились, что она и впрямь делает то, для чего предназначена. И — самое главное — используйте свои биологические знания по максимуму, потому что только это и делает вас компьютерным биологом. С другой стороны, полезно писать комментарии прямо по ходу написания программы: «эта функция/структура нужна для...», иначе уже через неделю вы потратите много времени, чтобы понять, что здесь происходит. Повторный запуск программы — это отличное повод для приведения кода в человеческий вид; вы просто будете делать это походу «вспоминания» вчерашней последовательности действий.
Используйте систему контроля версий
Использование контроля версий позволит более гибко управлять развитием кода, позволит легко возвращаться к предыдущим редакциям программы или переключаться между разными ветвями разработки, а также откроет возможность совместной разработки программы. Распространенные системы — такие как Git или Subversion — дадут возможность легкой публикации проекта в сети. Вы сделаете лучше прежде всего для себя, если не поленитесь написать несколько внятных README-файлов и положите их в нужные места проекта; это чрезвычайно вам поможет, если спустя месяцы или даже годы вам придется вернуться к старой программе. Документируйте программы и скрипты, чтобы было понятно, что они делают. Когда публикуете научную статью, хорошим тоном будет опубликовать также оригинальные программы, которые использовались для обсчета данных: это позволит другим использовать тот же метод и воспроизвести ваши результаты. Неплохо бы также вести электронный дневник, в котором был бы записан весь ход работы. Онлайн-репозитории, такие как Github, позволяют делать это, а также позволят вам хранить рабочие версии программы, что станет дополнительным уровнем бэкапа ваших наработок (см. таблицу 1).
| Задача | Инструменты |
|---|---|
| Совместная разработка программ | Сделайте ваш код (и, возможно, данные) доступными в сети с такими онлайн-хранилищами как Github, Sourceforge или Bitbucket. В интернете много руководств по использованию этих систем. Существуют также системы управления научными проектами, о которых рассказано в отдельной врезке. |
| Для сложных задач пишите скрипты и конвейеры | Для этого можно использовать как современные разработки, вроде Ruffus, так и проверенные временем классические UNIX-утилиты типа Make. Выбор конкретного инструментария зависит от личных предпочтений и любимого языка программирования |
| Сделайте ваши «конвейеры» доступными | Не исключено, что в командной строке вы себя чувствуете, как рыба в воде, но большинство ваших коллег, наверняка, нет. Созданные вами конвейеры можно оснащать графическими интерфейсами с помощью систем Galaxy или Taverna. |
| Инструменты разработчика (IDE) | Конечно, программы можно писать в любом текстовом редакторе, начиная с vi, но будет лучше, если вы освоите более продвинутые инструменты — такие как текстовый редактор Emacs или полнофункциональную среду разработки типа Eclipse. И, опять же, конкретный выбор будет основан на ваших предпочтениях и любимом языке программирования. |
Заразная болезнь конвейерит
Конвейер (pipeline) — программная цепочка из нескольких или многих инструкций, позволяющая проводить в точности те же операции на новом наборе данных. Конвейеры и скрипты незаменимы в работе компьютерного биолога, но они также могут загнать ваше сознание в прокрустово ложе скрипта и в корне прервать полет фантазии.
Поэтому нужно предупредить: не пишите всеобъемлющих скриптов слишком рано. Сначала убедитесь, что ваша задумка сработала, и только потом программируйте конвейер. Да и в этом случае трижды подумайте: а оно надо? Точно ли конвейер в этом случае сэкономит время и позволит вывести исследование на новый уровень? Смогут ли (и захотят ли!) этой программой пользоваться другие люди? Если в дальнейшем никто, кроме вас, этой программой пользоваться не собирается, то проще будет оставить ее на уровне работающего скрипта и не увлекаться слишком полной автоматизацией процесса. Тем более — если работа была разовая, в вряд ли заново придется делать то же самое. В этом случае достаточно просто записать в журнал проделанное и с чувством выполненного долга двигаться дальше. В любом случае, вежливо будет в статье написать «scripts are freely available at request», если вы и впрямь не против поделиться своим решением.
Полет фантазии
Ну конечно же, вы можете. Что захотите — то и можете. В том смысле, что креатив и смелая фантазия в работе компьютерного биолога совершенно необходимы, потому что иначе сделать ничего интересного не получится. Адаптируйте существующие методы, создавайте новые, предвидьте успех и не бойтесь неудачи. В этой области очень многого можно достичь, просто лазая по интернету и общаясь с коллегами в лаборатории или в сети. Самообразование не только научит вас решать конкретные проблемы — оно научит вас постоянно учиться.
Запишитесь на онлайн-курсы (см. табл. 2), но это будет только начало, а не конец обучения. Лишь смерть обрывает обучение по-настоящему творческого человека.
| Полезный навык | Ресурсы |
|---|---|
| Онлайн-курсы (Massive open online courses) | Сейчас такие курсы переживают взрыв популярности, и уже предлагают крайне широкий спектр тематик для изучения прямо через интернет. На сайтах Coursera, Udacity, edX и Kahn Academy есть масса полезного из области биоинформатики, геномики, компьютерной биологии, статистики и разнообразного моделирования. |
| Обучение программированию | Codeacademy и Code School не являются чем-то заточенным под биологию, но хорошо подходят для начал программирования. Потом можно продолжить с курсом «Python для биологов». Множество хороших примеров доступно на сайте http://software-carpentry.org. |
| Решение биоинформатических задач | Практическое изучение биоинформатики путем изучения программирования и соревнования с другими участниками проекта доступно на российском сервисе Rosalind. |
| Международные организации | GOBLET — международная организация по биоинформатическому образованию, а ELIXIR — европейское объединение, обеспечивающее различную информационную поддержку и инфраструктуру для исследований в области наук о жизни. |
| Блоги и листы подписки | В сети есть масса блогов и списков рассылки для компьютерных биологов, например http://stephenturner.us/p/edu и http://ged.msu.edu/angus/bioinformatics-courses.html. Для вычислительных химиков есть еще CCL.net. |
| «Локальные» российские ресурсы | |
| Обучение основам биоинформатики (курсы и свободное посещение) | Московская школа биоинформатики даст основные навыки в этой сфере, а курс по работе с данными высокопроизводительного секвенирования расскажет, как получают полные последовательности геномов. Институт биоинформатики в Санкт-Петербурге знакомит студентов с основами биоинформатики на примере реальных научных исследований (также проходит Летняя школа). |
| Вузы, в которых преподают биоинформатику |
|
| Опыт работы с Linux/Unix | Помощь в установке и настройке одного из дистрибутивов Linux вам могут помочь в сообществах Russian Fedora или Ubuntu. Также вы можете обратиться с вопросами на http://linux.org.ru; более того, на этом ресурсе можно получить и ответы на некоторые научные вопросы. |
Никого не слушай
При отработке статистических методик часто делают такой эксперимент: генерируют большие массивы случайных данных, которые случайно же обозначают как «рабочую выборку» или «контроль». А затем к этим данным применяют статистический критерий, который должен выявить различия между данными, которые исходно не различаются, и... Для многих «выборок» p-значение частенько указывает на статистически значимое различие. Биологические наборы данных, например, полученные из геномного анализа или из скрининговых тестов, также полны случайного «шума» и часто огромны по размерам. Будьте готовы к тому, что при анализе подобных данных вам придется столкнуться с ложноположительными и ложноотрицательными результатами, а также в исходные данные может вкрасться систематическая ошибка, возникшая из-за особенностей эксперимента или экспериментатора.
Даже у биологов, искушенных в статистике, частенько возникает соблазн наплевать на осторожность и углубиться в эксперименты с программой или скриптом, давшими интересный результат. Однако тут всегда необходима осторожность, которая подсказывает, что необходимо рассматривать любой результат как потенциально ошибочный и провести дополнительные проверки на этот счет. Если один и тот же результат удается получить с помощью разных подходов, тогда уверенность в правильности каждого из них возрастет. И, тем не менее, большинство таких «открытий» требуют экспериментального подтверждения, чтобы откинуть оставшиеся сомнения.
Самое важное — что для интерпретации полученных на компьютере результатов нужно хорошее биологическое образование и чутье. И даже то, что программа или скрипт работают правильно, еще не гарантирует, что полученный результат не является артефактом или просто неверной трактовкой каких-то других явлений.

Любимые слова компьютерных биологов.
сайт nsaunders
Верный инструментарий
Обязательно освойте командную строку UNIX/Linux. Бóльшая часть биоинформатических программ имеет интерфейс командной строки. На самом деле, она чрезвычайно мощная, позволяет в тонкостях контролировать рабочие задачи, запускать программы на параллельное исполнение, и, что немаловажно, контролировать работу утилит и перезапускать их прямо через текстовый терминал, хоть с мобильного телефона. Это одно из преимуществ работы биоинформатиков — работать можно где угодно, был бы под рукой компьютер или планшет, а также выход в интернет. Освойте параллельные вычисления, потому что они позволяют запускать сотни задач одновременно и многократно повышать производительность работы. Обязательно нужно уметь хоть чуть-чуть программировать, хотя выбор конкретного языка программирования не играет большой роли: у всех у них есть свои преимущества и недостатки, и иногда нужно комбинировать несколько разных языков, чтобы сделать работу быстрее.
Помните, что выбор более популярного языка позволит вам пользоваться бóльшим набором существующих библиотек и подпрограмм, которые позволят не изобретать велосипед, а сосредоточиться на своей работе. Примером такого «склада» наработок является Open Bioinformatics foundation. Старайтесь не использовать Microsoft Excel (только для вывода таблиц, которые будут читать некомпьютерные биологи, которые только с ним и умеют работать). Это хорошая программа, но для обработки большого количества данных она все-таки подходит плохо. Лучше всего хранить экспериментальные данные в структурированных текстовых файлах (хороший вариант для таблиц — csv) или в SQL-базе — это позволит получать доступ к информации прямо из вашей программы.
И, да, делайте бэкапы!
Элементарно, Ватсон!
Раз уж вы станете компьютерным биологом, вам все время придется возиться с данными. Они хранят множество историй, и выловить эти истории оттуда — ваш профессиональный долг. Однако скорее всего сделать это будет не так-то просто. Нужно постоянно держать в голове смысл проведенного эксперимента и схему анализа данных, а также денно и нощно обдумывать, какой же биологический смысл кроется в полученных результатах. И не является ли гипотетический подмеченный вами смысл тривиальным следствием ошибок анализа или артефактов в данных.
Чтобы все это имело смысл, нужно общаться с другими специалистами, которые получали эти экспериментальные данные, и стараться собрать картину по кусочкам. Предлагайте дополнительные эксперименты, которые смогут подтвердить или опровергнуть выдвинутую вами гипотезу. Станьте детективом, докопайтесь до ответа.
Кто-то это уже сделал. Так найдите их и спросите!
Какая бы хитрая не была проблема и как бы не был нов метод, всегда есть вероятность, что люди уже занимались тем, с чем пришлось столкнуться вам. Есть два сайта, на которых обсуждают возникшие в исследованиях проблемы — BioStars и SeqAnswers (а чисто программистские вопросы — Stack Overflow). Иногда можно получить дельный совет даже в твиттере. Поищите в интернете, кто в этой стране и в мире занимается похожими вопросами и свяжитесь с ними (см. таблицу 3).
| Лаборатория | Город | Чем занимаются |
|---|---|---|
| Группа молекулярного моделирования на биологическом факультете МГУ | Москва | Молекулярная динамика белков и пептидов |
| Группа вычислительной структурной биологии, биоинформатическая группа и лаборатория эволюционной геномики на факультете биоинженерии и биоинформатики МГУ | Москва |
|
| Лаборатория химической кибернетики и группа компьютерного молекулярного дизайна на химическом факультете МГУ | Москва |
|
| Лаборатория биокатализа и биотрансформаций и Отдел математических методов в биологии НИИ физико-химической биологии МГУ | Москва |
|
| Лаборатория моделирования биомолекулярных систем в Институте биоорганической химии РАН | Москва | Молекулярное моделирование биомембран и мембранных белков, а также биологически активных веществ |
| Лаборатории структурной биоинформатики и структурно-функционального конструирования лекарств в Институте биомедицинской химии РАМН | Москва | Компьютерное моделирование комплексов белков с белками и лекарствами, драг-дизайн, фармакология, изучение связей «структура—активность» |
| Учебно-Научный центр «Биоинформатика» и еще несколько биоинформатических групп в Институте Проблем Передачи Информации РАН | Москва | Системная биология, анализ пространственных структур биомолекул, сравнительная геномика.Организуют Московский биоинформатический семинар, Московскую школу биоинформатики и конференцию «Moscow Conference for Molecular Computational Biology». |
| Лаборатория системной биологии и вычислительной генетики и группа биоинформатики в Институте общей генетики РАН | Москва | Поиск функциональных мотивов (сайтов связывания транскрипционных факторов и т.д.) в последовательностях ДНК |
| Лаборатория биоинформатики и системной биологии в Институте молекулярной биологии РАН | Москва | Методы биоинформатики и поиска функциональных мотивов, предсказание предрасположенности к заболеваниям |
| Лаборатория биоинформатики в НИИ Физико-химической медицины | Москва | Проблемы метагеномики и протеомики |
| Лаборатория алгоритмической биологии Академического университета РАН | Санкт-Петербург | Проблемы «сборки» и анализа геномов |
| Лаборатория «Алгоритмы сборки геномных последовательностей» национального исследовательского университета информационных технологий, механики и оптики | Санкт-Петербург | Проблемы «сборки» и анализа геномов |
| Группа биоинформатики и функциональной геномики Института Цитологии РАН | Санкт-Петербург | Изучение функционального значения общей структуры генома |
| Лаборатории функциональной геномики и клеточного стресса и механизмов функционирования клеточного генома Института биофизики клетки РАН | Пущино |
|
| Лаборатория прикладной математики в Институте математических проблем биологии РАН | Пущино | Вторичная структура РНК, альтернативный сплайсинг |
| Лаборатория физики белка Института белка РАН | Пущино | Теоретическое и экспериментальное изучение процессов сворачивания белковых молекул |
| Отдел системной биологии Института цитологии и генетики СО РАН | Новосибирск | Постгеномная биоинформатика. Компьютерный анализ и моделирование молекулярно-генетических систем. Генные сети. Модели эволюции микроорганизмов. |
| Группа лаборатории экологической биохимии Института биологии КарНЦ РАН | Петрозаводск | Молекулярное моделирование биомембран |
| Мы отдаем себе отчет, что в одной таблице нельзя перечислить все стóящие научные группы. Если мы забыли кого-то, то с удовольствием добавим. Таблица подготовлена Еленой Чуклиной (Московский физико-технический институт / Учебно-научный центр «Биоинформатика» Института проблем передачи информации РАН). | ||
В довершение можно сказать, что в интернете есть масса форумов и юзергрупп, где можно задать интересующие вопросы. Установите себе линукс и начните изучать в онлайне что-нибудь биоинформатическое. При должном упорстве вы удивитесь, как многого можно достичь, имея просто компьютер и выход в интернет!
Статья написана по мотивам эссе в журнале Nature Biotechnology [10] при участии Артура Залевского и Елены Чуклиной.
Автор этой заметки делает вид, что моделирует на компьютере взаимодействие лиганд-связывающего домена никотинового ацетилхолинового рецептора типа α7 с одним из природных нейромодуляторов.
Литература
- In vivo — in vitro — in silico;
- Пространственно-временное моделирование в биологии;
- Торжество компьютерных методов: предсказание строения белков;
- Молекулярная динамика биомолекул. Часть I. История полувековой давности;
- Компьютерные игры в молекулярную биофизику биологических мембран;
- На заре молекулярной графики;
- Как прочитать эволюцию по генам?;
- Вычислительное будущее биологии;
- Код жизни: прочесть не значит понять;
- Nick Loman, Mick Watson. (2013). So you want to be a computational biologist?. Nat Biotechnol. 31, 996-998.



Комментарии
0Чтобы оставить комментарий, необходимо
войти